StarPU Micro Benchmarks
Table of Contents
- Raw data
- By clicking on a plot, you will get more detailed plots over last year, last 6 months, last month and last week
- The black line at revision 11490 (2013-10-23) marks when we changed the system where the microbenchs are run.
- The purle line at revision 12298.5 (2014-02-26) marks when the default scheduler was switched to use tree-based worker iterators, and the green line at revision 17026.5 (2016-03-24) marks when this was reverted.
- The black line at revision 19182.5 (2016-11-02) marks when we changed again the system where the microbenchs are run.
- The black lines at revisions 19320.5 (2016-11-29) and 19451.5 (2016-12-14) mark the period when the kernel was switched to 4.8.11 instead of the usual Debian 4.5.0
- The black line at 2022-05-12 marks when we changed again the system where the microbenchs ar run.
Tasks Overhead
This is the time to submit a task, from the main thread, with a tag dependency:
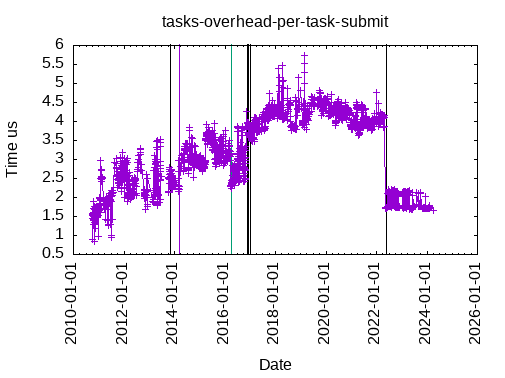
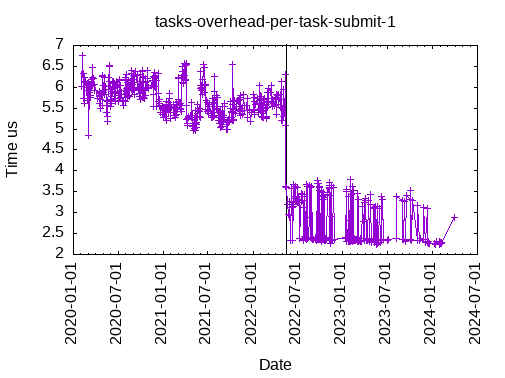
This is the time to submit a task, from the main thread, with one data dependency:
This is the time to execute an empty tasks, with a tag dependency:
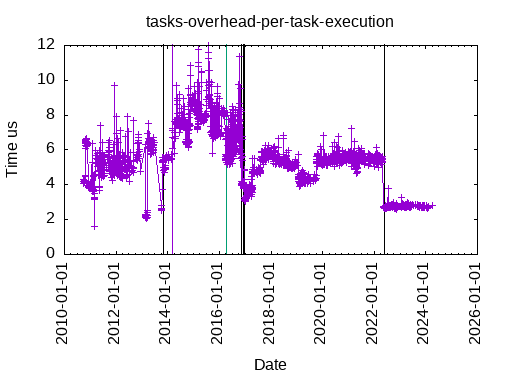
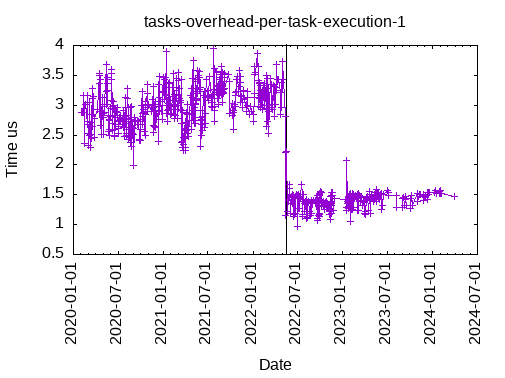
This is the time to execute an empty tasks, with one data:
This is the total time to submit & execute an empty task, with a tag dependency:
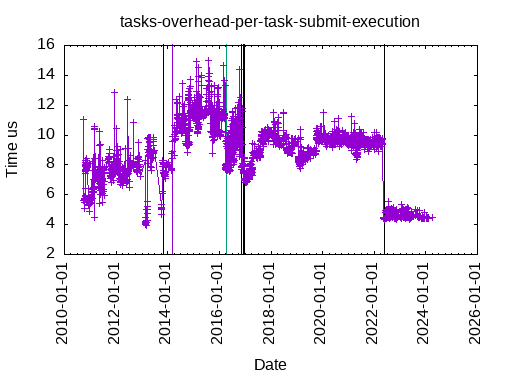
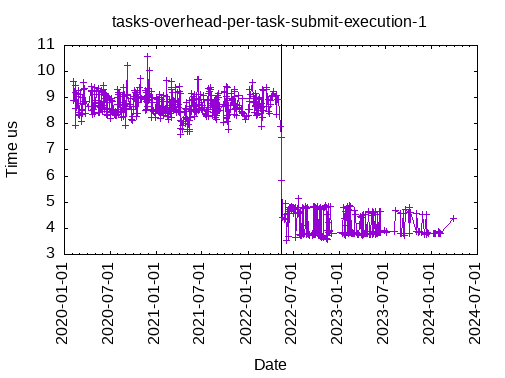
This is the total time to submit & execute an empty task, with one data dependency:
Synchronous Tasks Overhead
This is the total time to submit & execute a synchronous task:
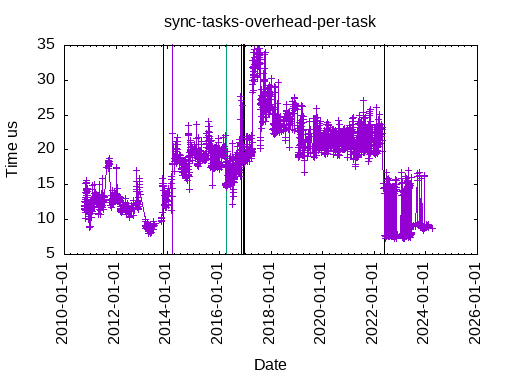
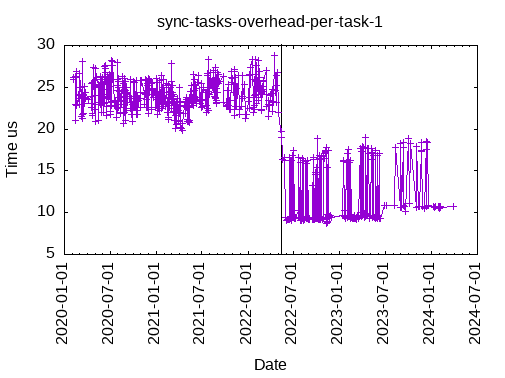
This is the total time to submit & execute a synchronous task, with one data dependency:
Asynchronous Tasks Overhead
This is the total time to submit & execute an asynchronous task without dependencies:
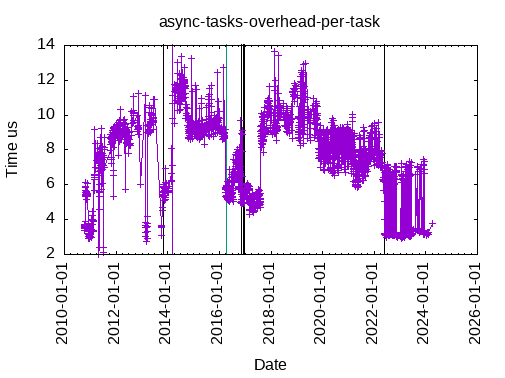
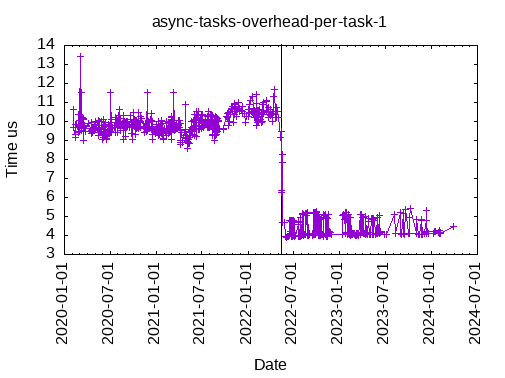
This is the total time to submit & execute an asynchronous task with one data dependency:
Bandwidth Overhead
- This shows the memcpy speed obtained by an increasing number of cores in parallel. The main reference is "alone" where other cores are completely idle (no thread). Secondary references are "nop" and "sync" where other cores are doing resp. "rep; nop", and actively checking for a global termination variable. The other curves show the case when other cores are running the scheduler looking for tasks to perform.
- There are two sets of curves: the lower ones are obtained by filling the system contiguously. The upper ones ("interleaved") are obtained by skipping every other core, thus more quickly spanning over multiple NUMA nodes and achieving more bandwidth, but also leaving idle every other core, possibly disturbing the memcpy transfer.

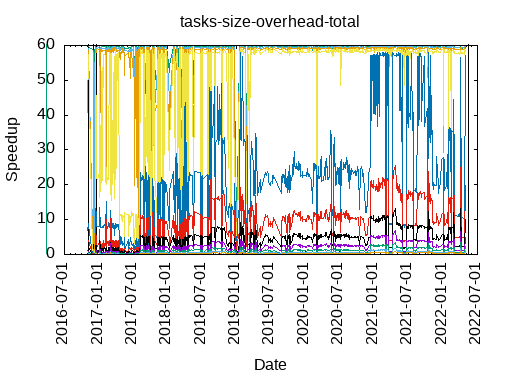
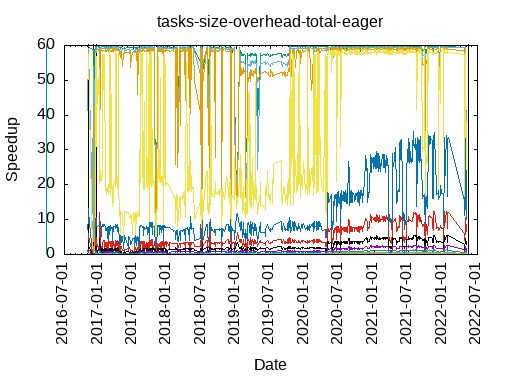
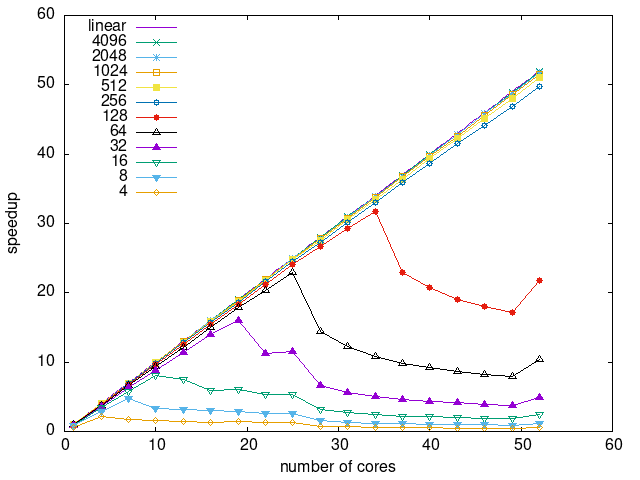
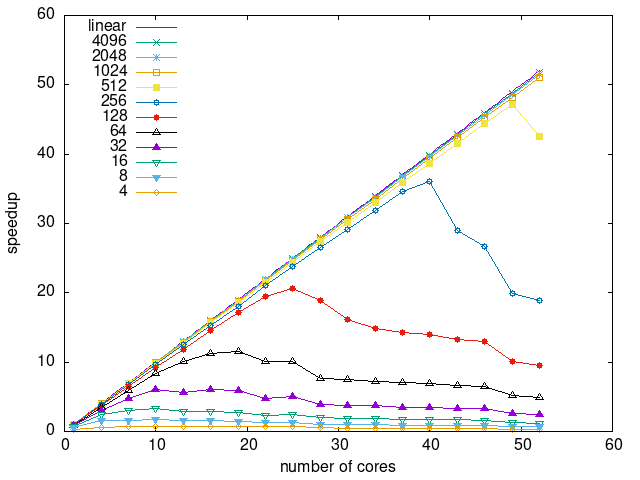
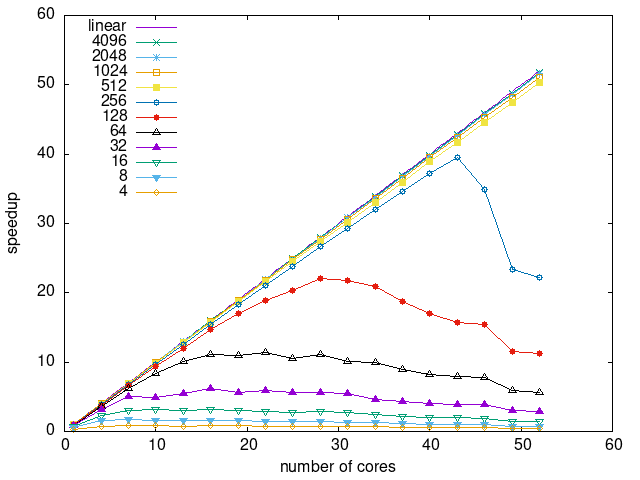
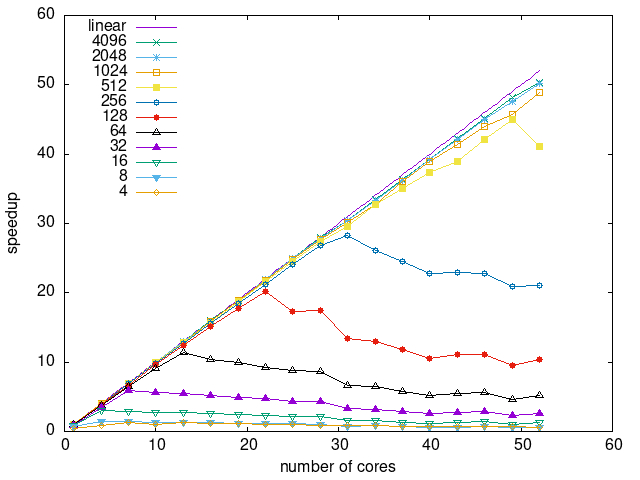
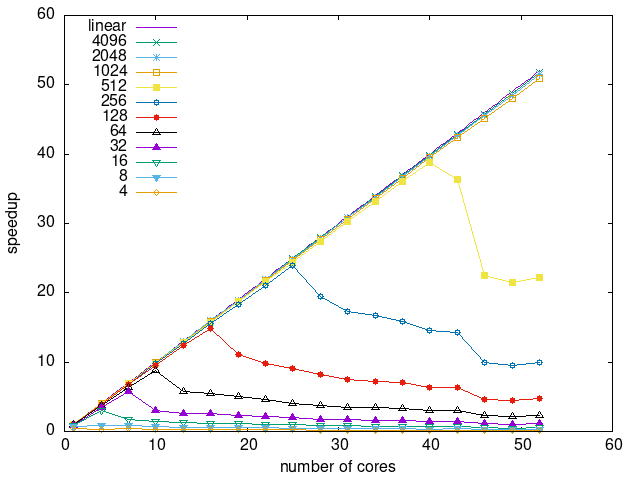
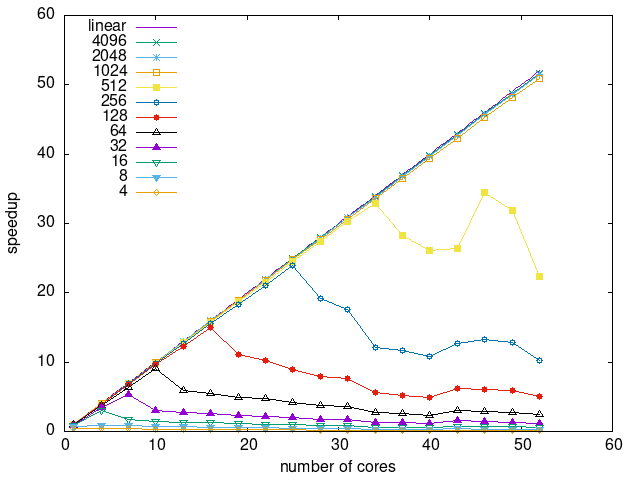
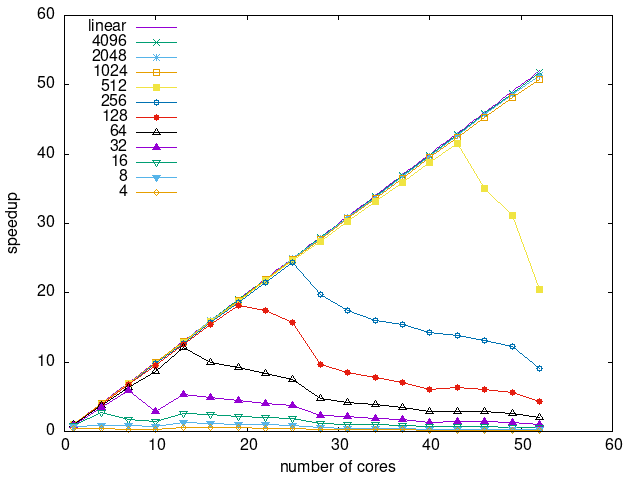
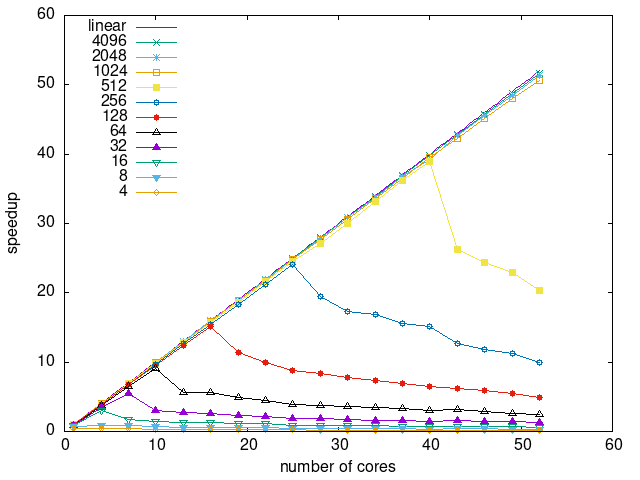
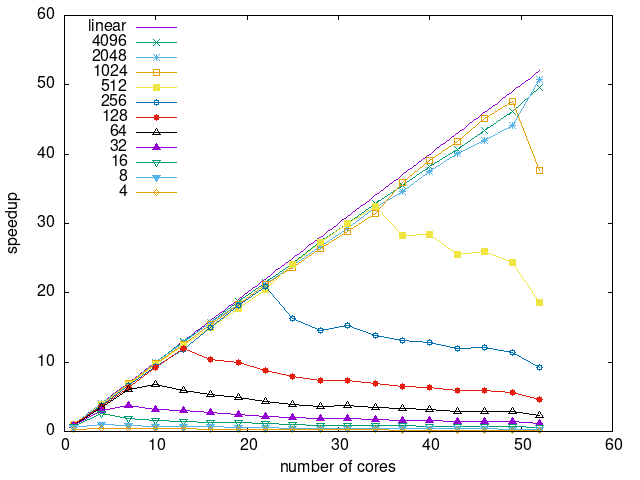
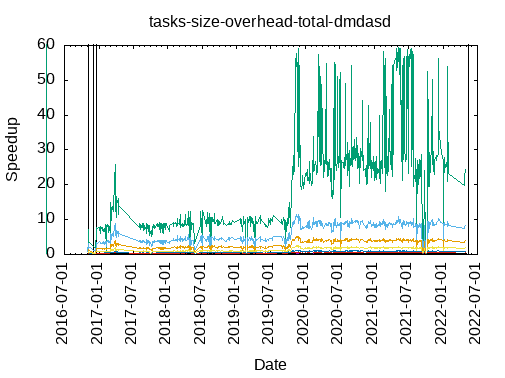
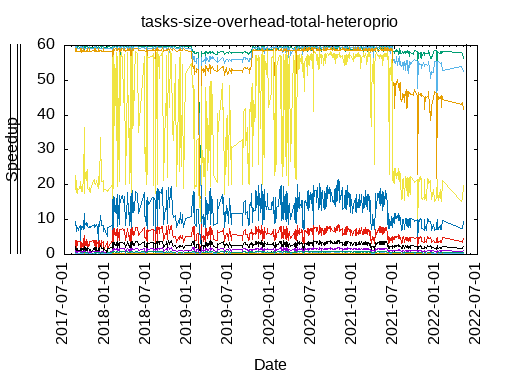
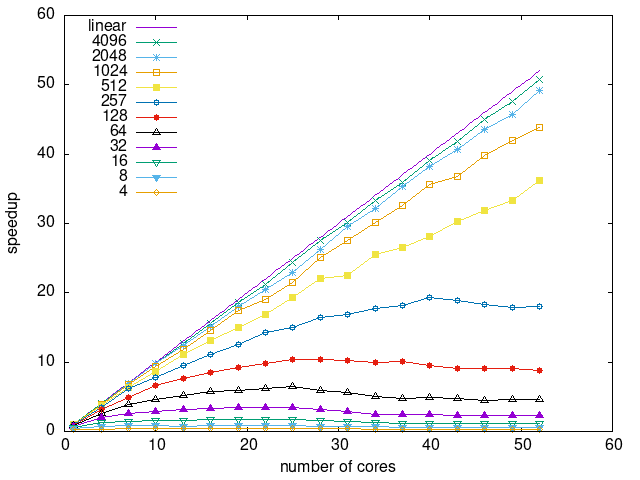
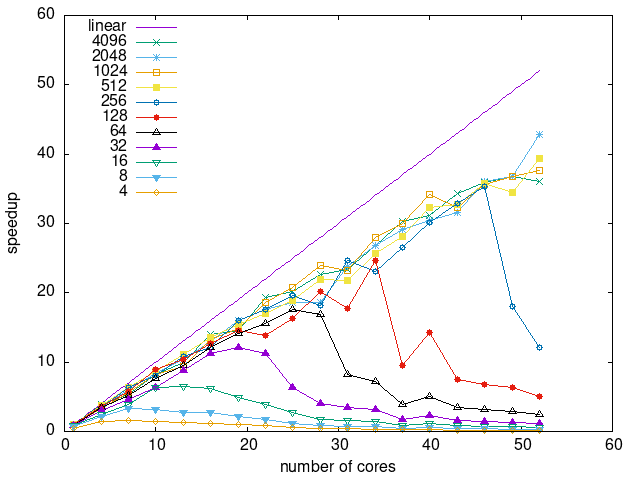
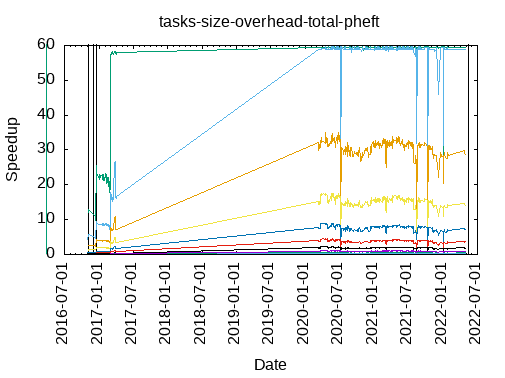
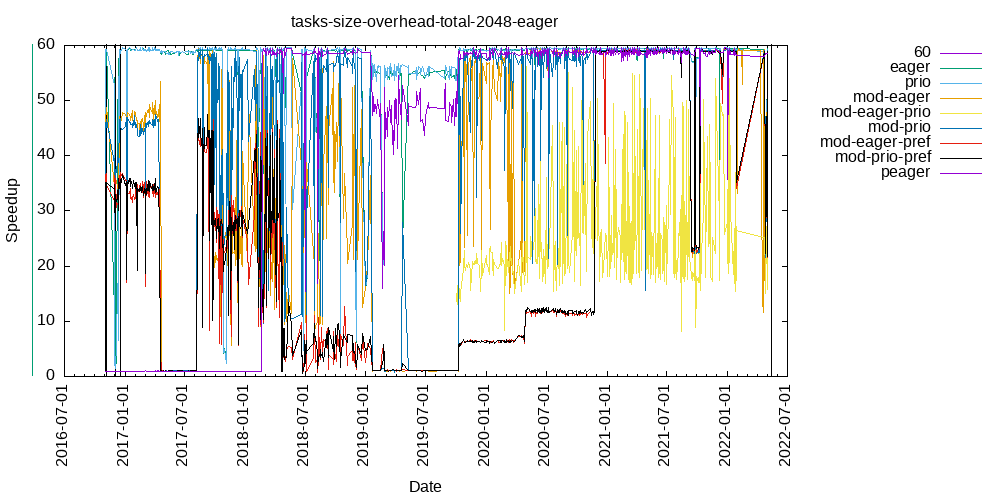
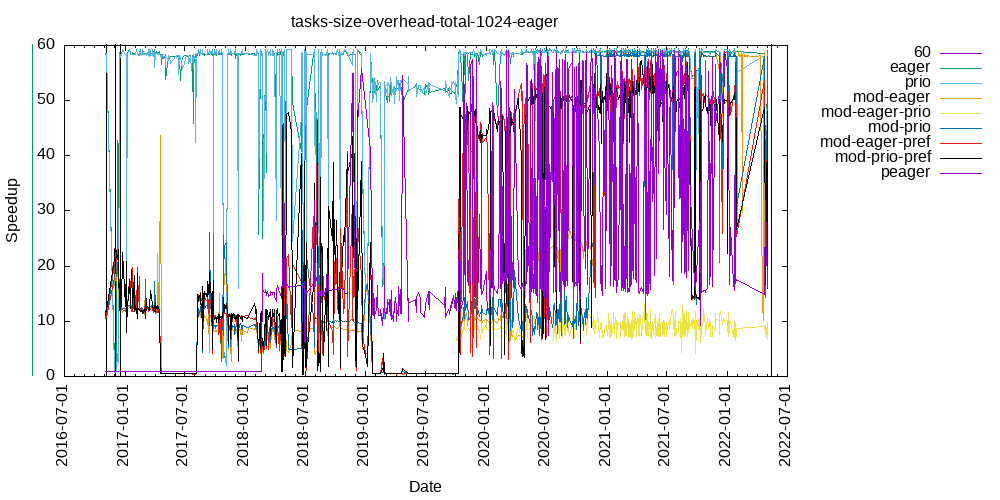
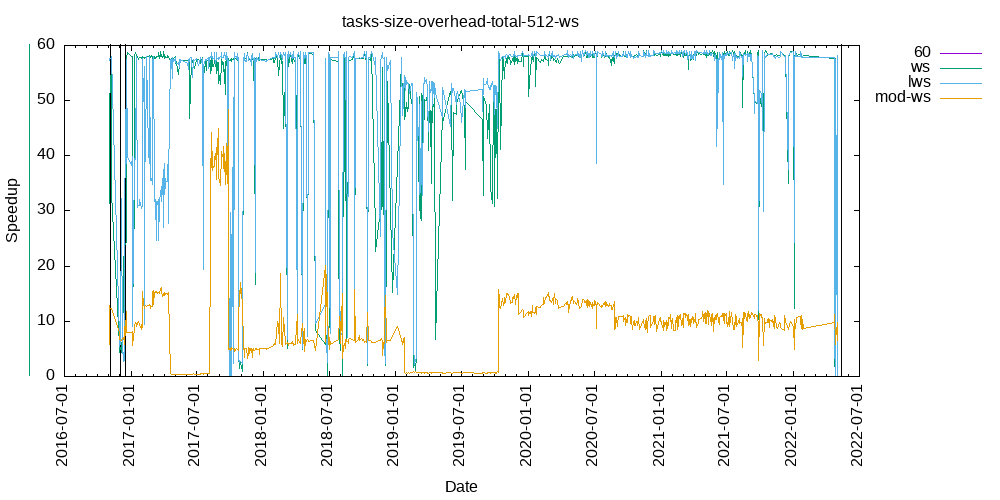
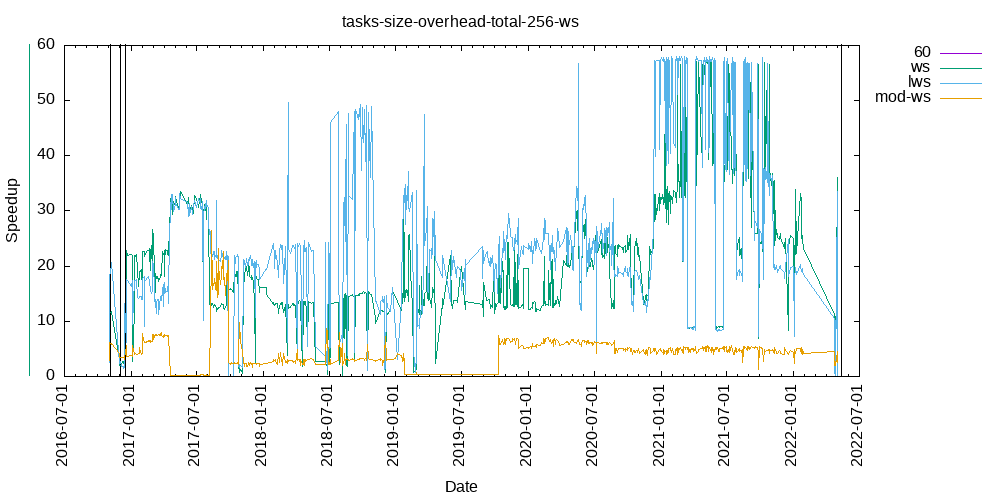
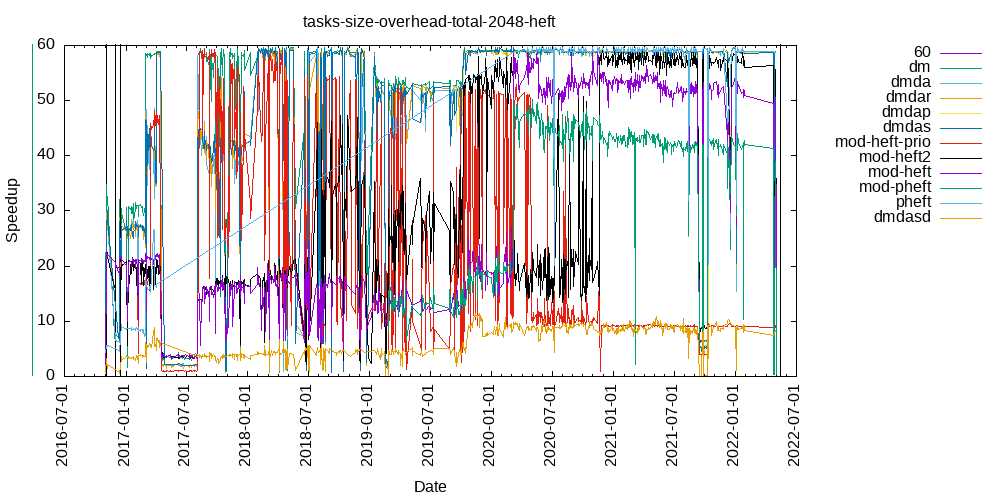
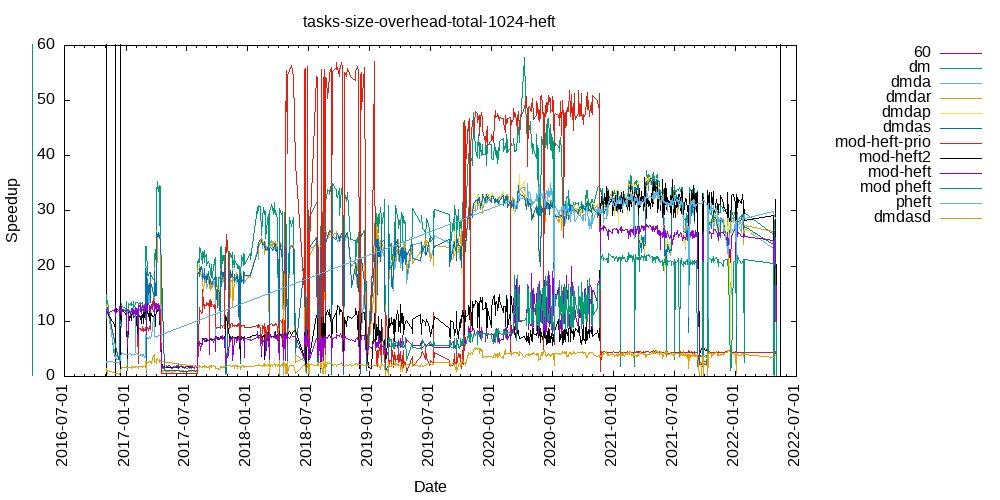
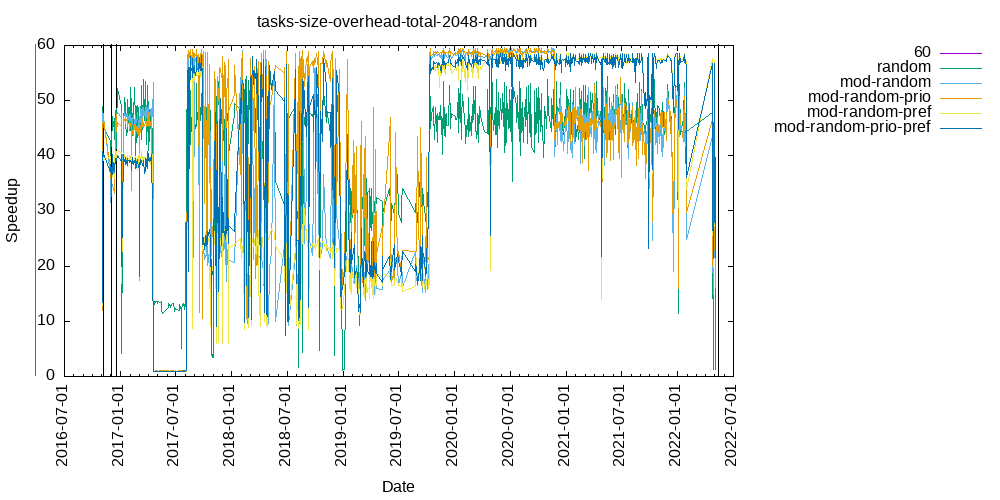
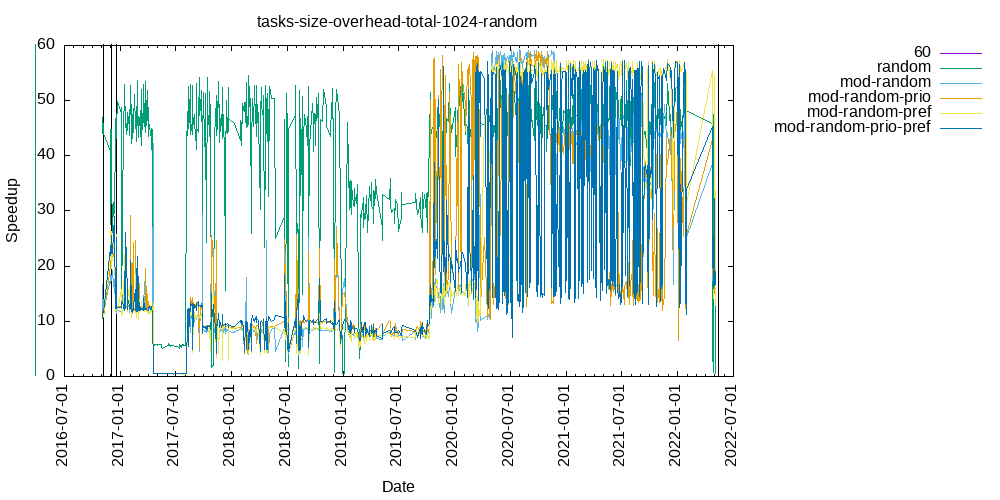
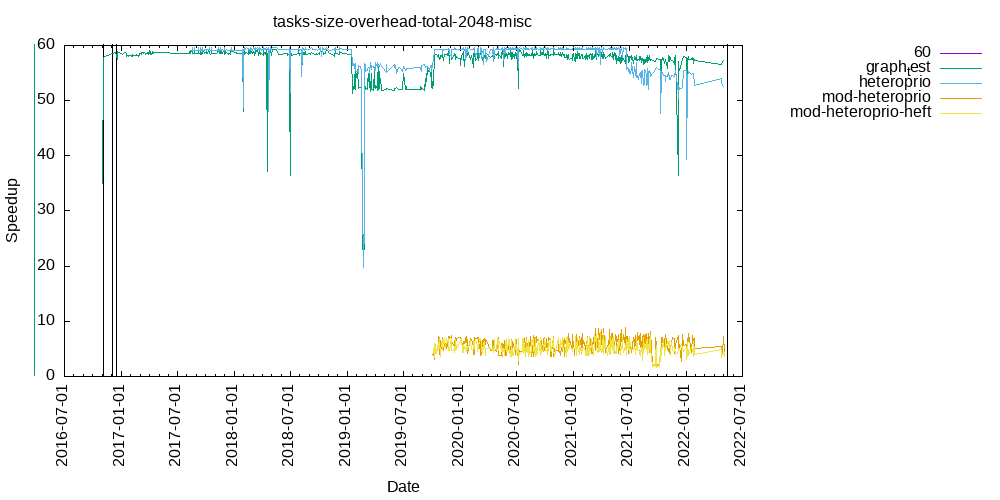
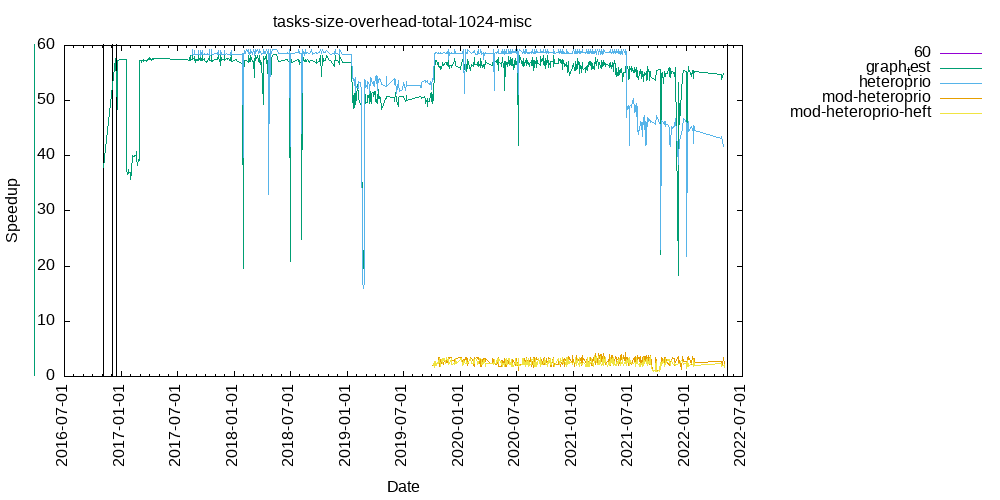
Tasks size Overhead
- This shows the speedup of running small tasks sizes on 60 cores of a 64-core machine. The highest curve (in blue) is for 4096µs tasks, the next curve (in green) is for 2048µs tasks, the next curve (in purple) is for 1024µs tasks, etc.
- eager
 |
 |
- modular-eager-prefetching
 |
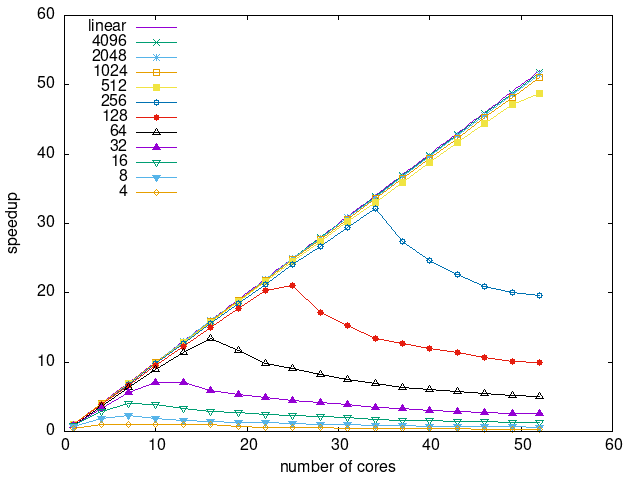 |
- modular-eager
 |
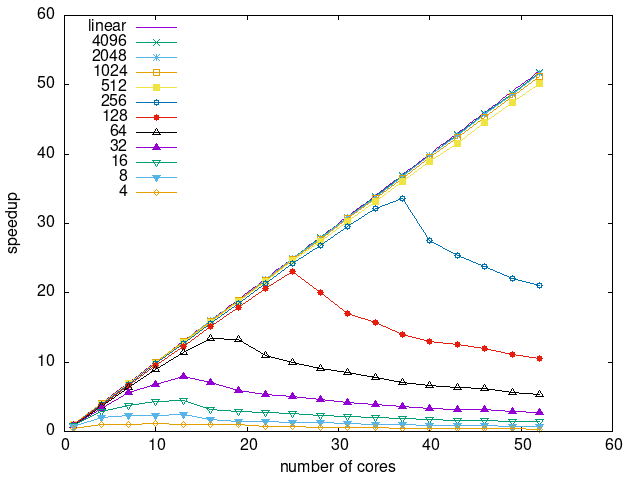 |
- prio
 |
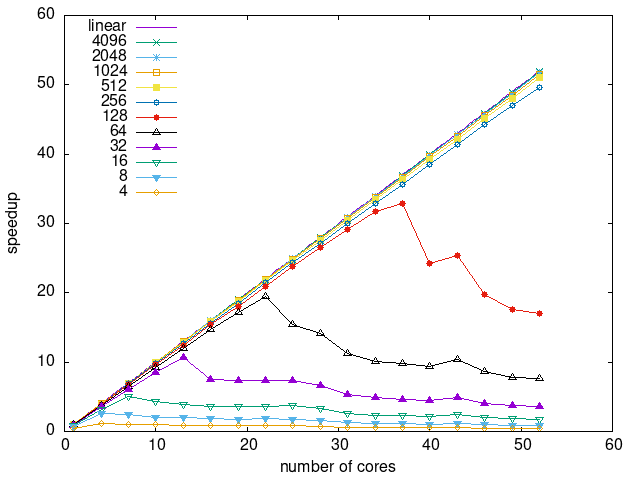 |
- modular-prio-prefetching
 |
 |
- modular-prio
 |
 |
- modular-eager-prio
 |
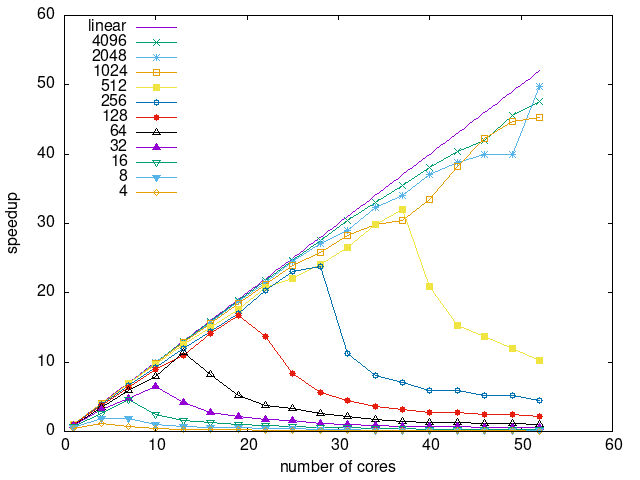 |
- ws
 |
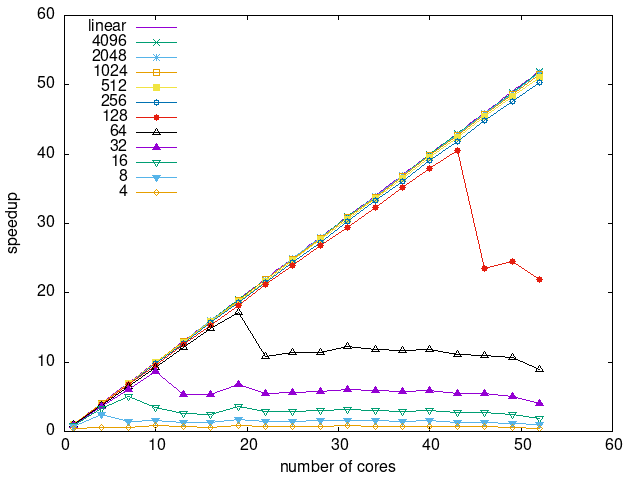 |
- modular-ws
 |
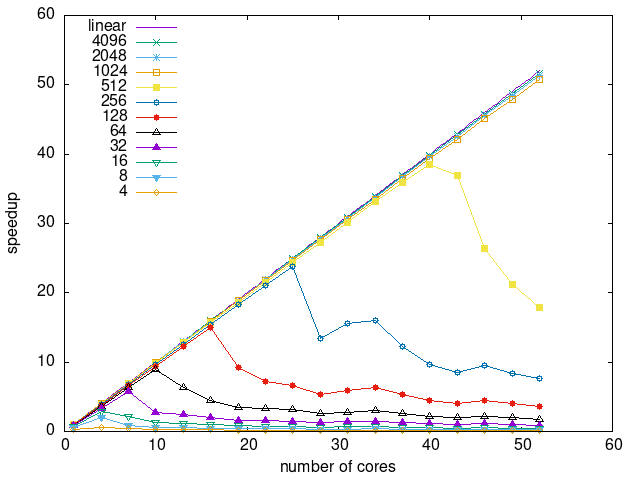 |
- lws
 |
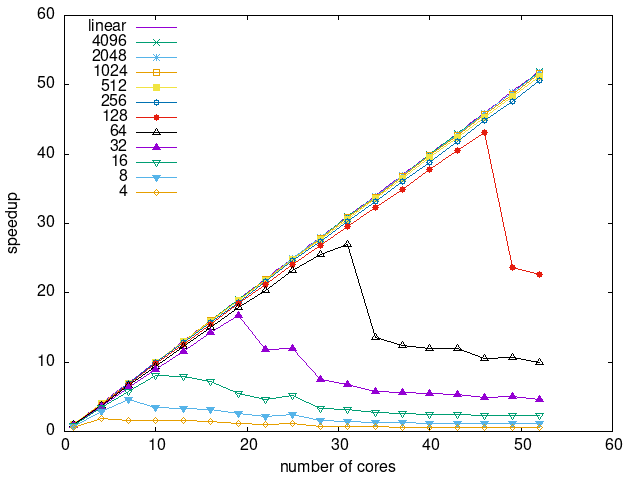 |
- graph_test
 |
 |
- dm
 |
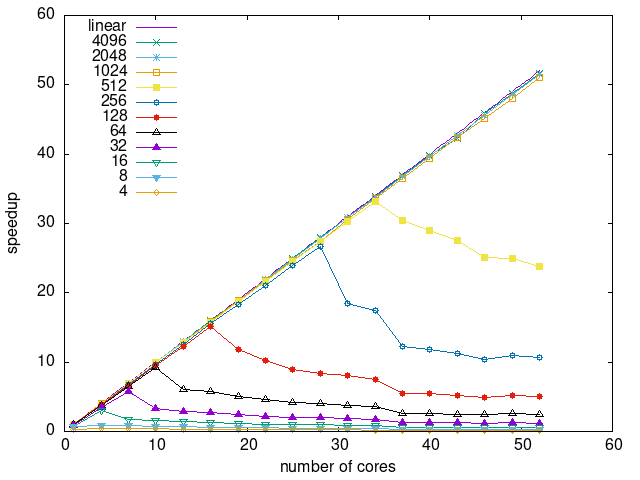 |
- dmda
 |
 |
- dmdar
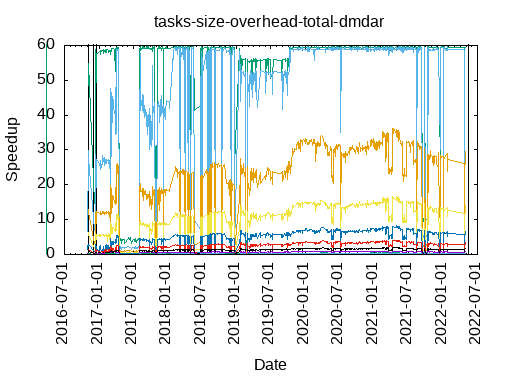 |
 |
- dmdap
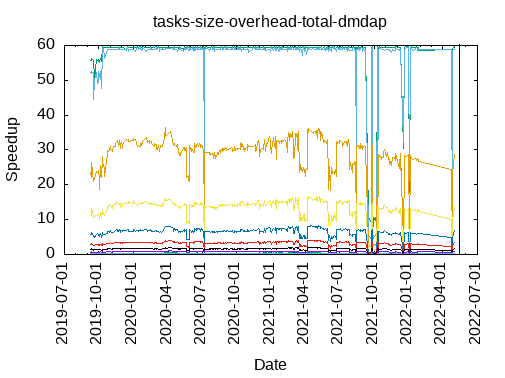 |
 |
- dmdas
 |
 |
- modular-heft2
 |
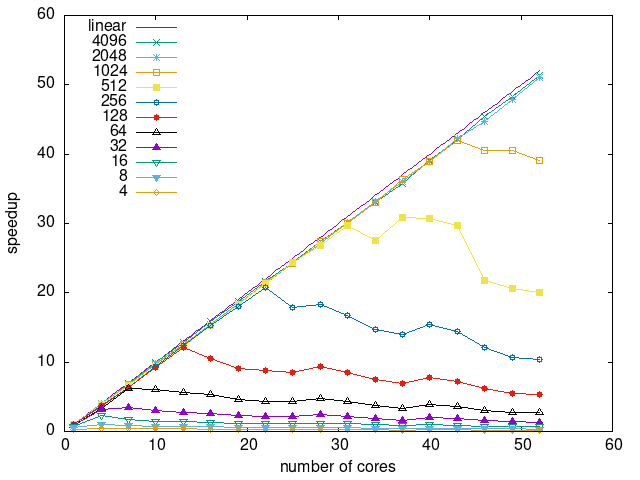 |
- modular-heft
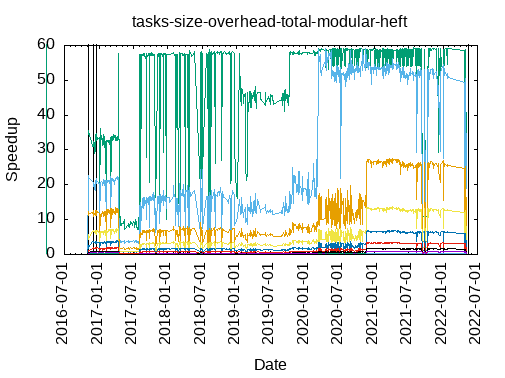 |
 |
- modular-heft-prio
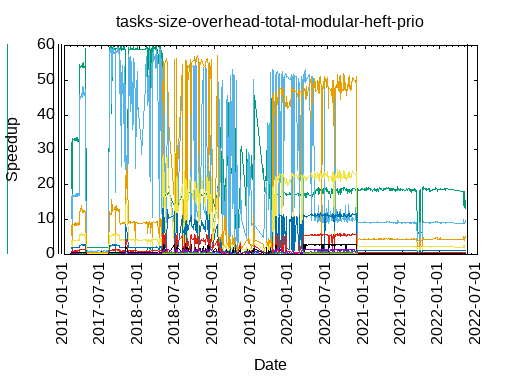 |
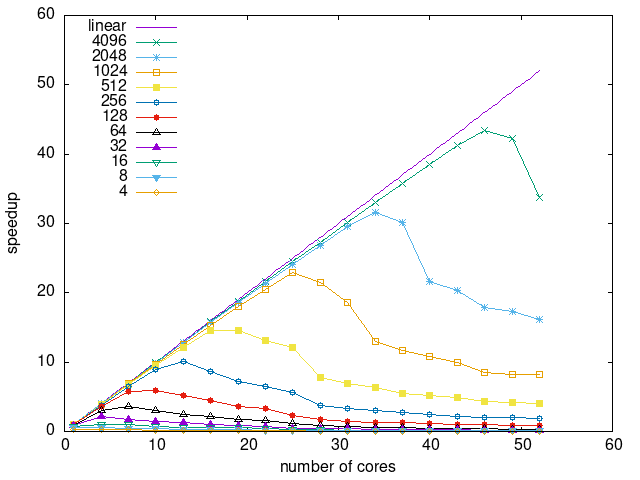 |
- modular-heteroprio
 |
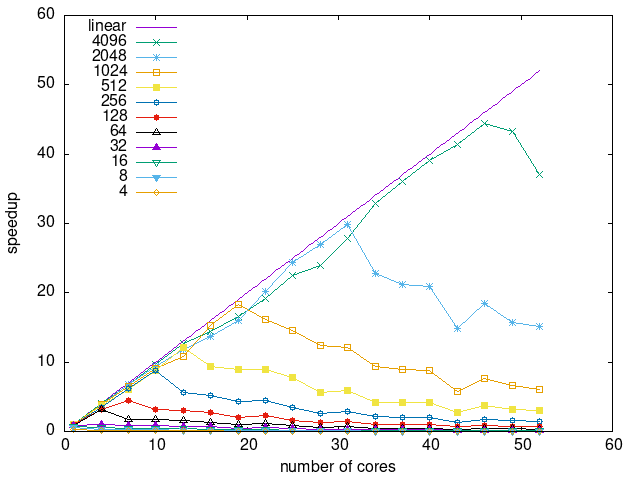 |
- modular-gemm
 |
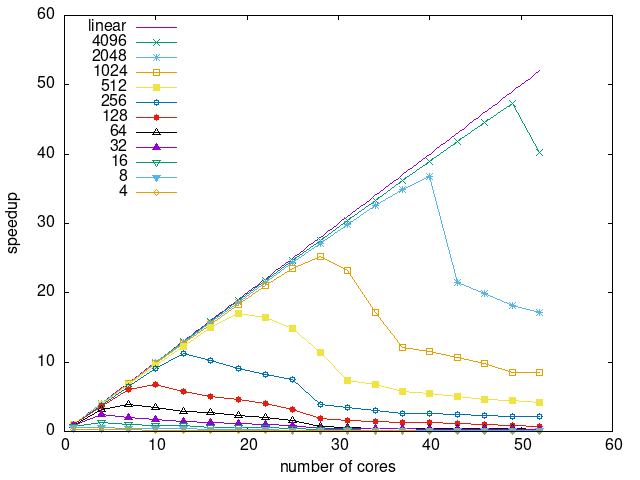 |
- dmdasd
 |
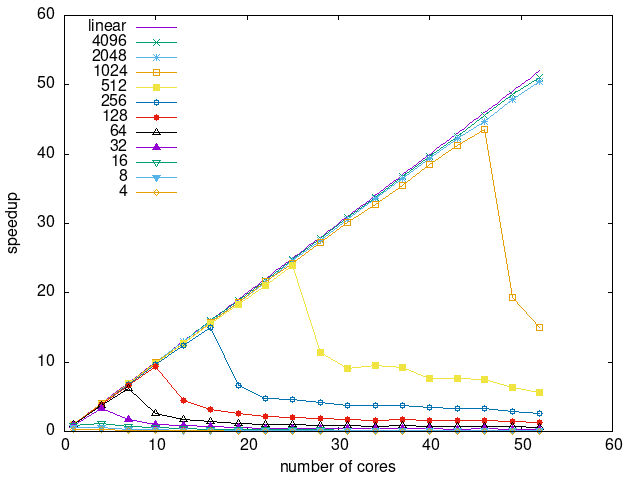 |
- heteroprio
 |
 |
- random
 |
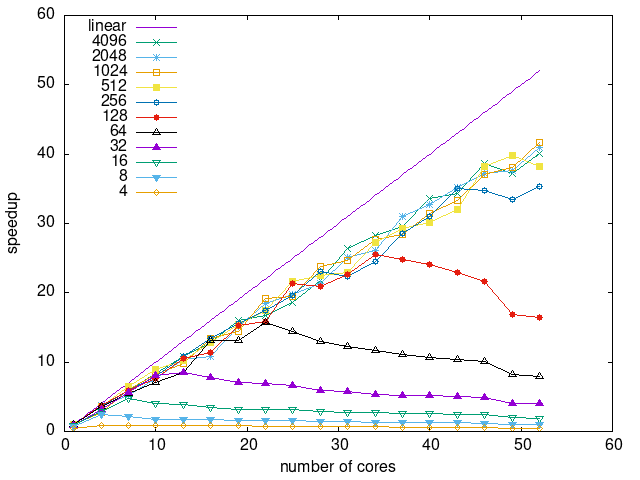 |
- modular-random
 |
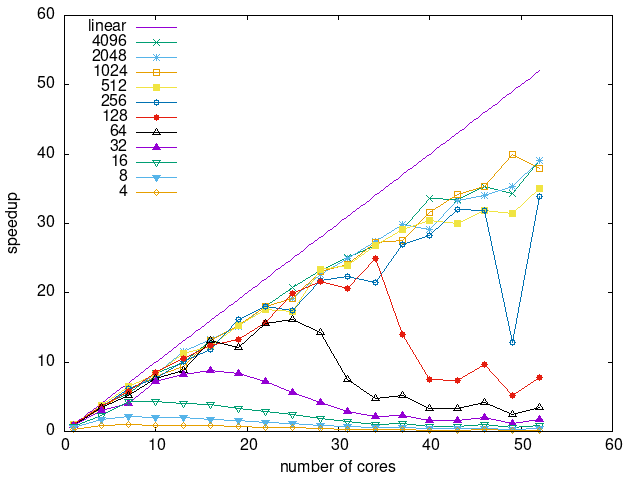 |
- modular-random-prefetching
 |
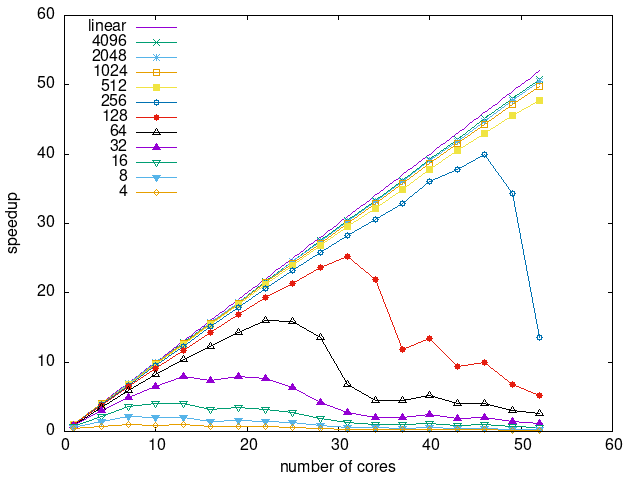 |
- modular-random-prio
 |
 |
- modular-random-prio-prefetching
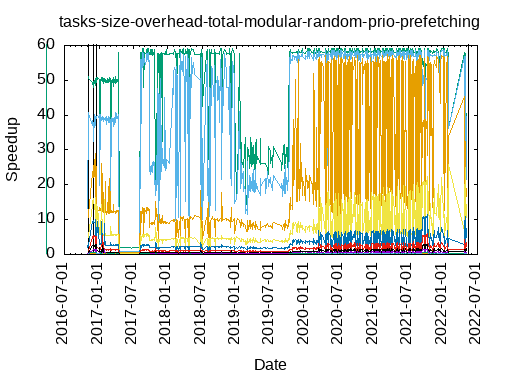 |
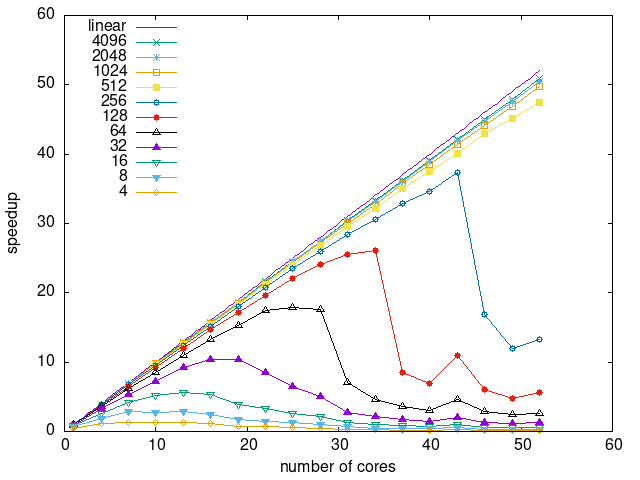 |
- peager
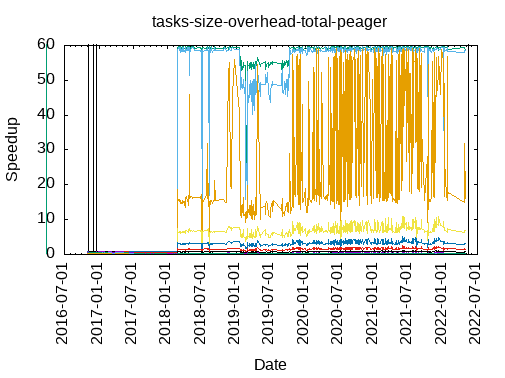 |
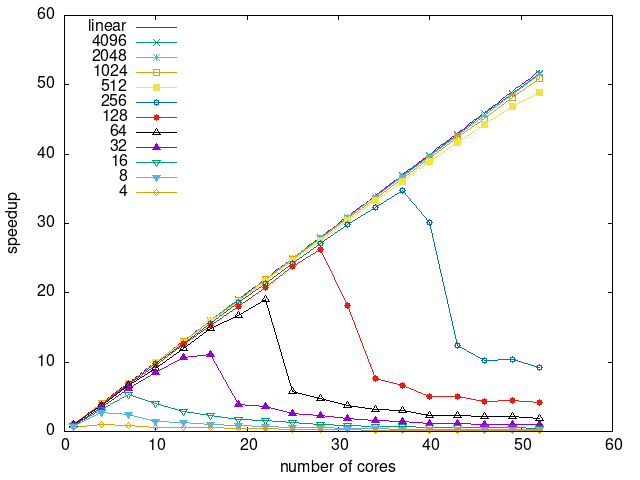 |
- pheft
 |
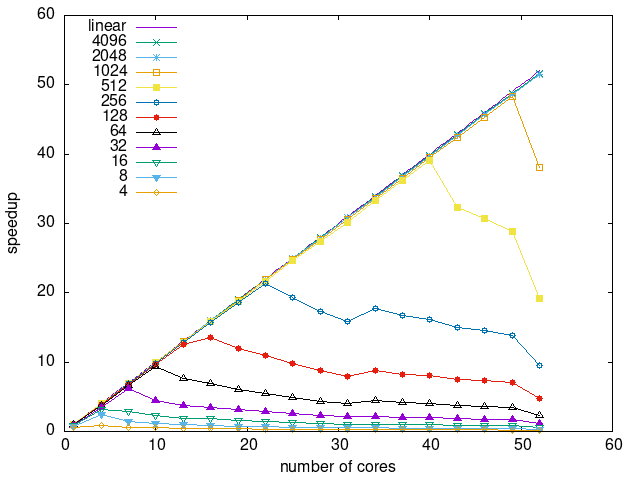 |
- eager
- ws
- heft
- random
- misc
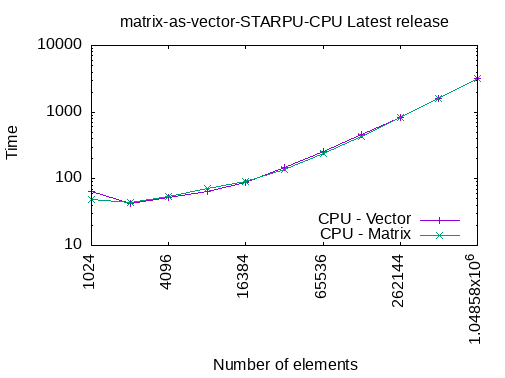
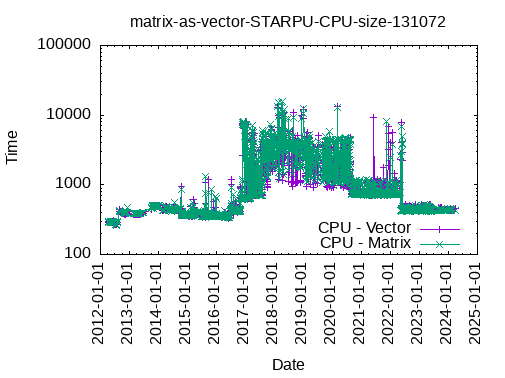
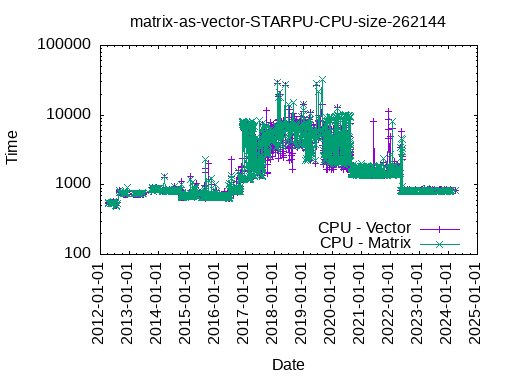
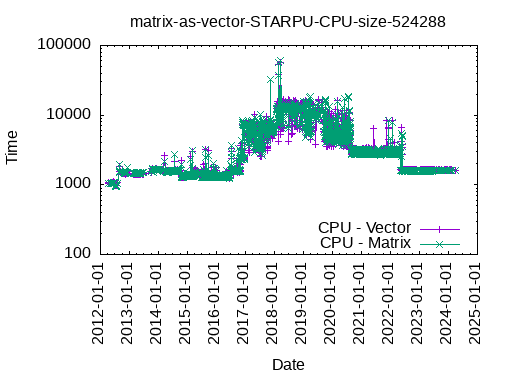
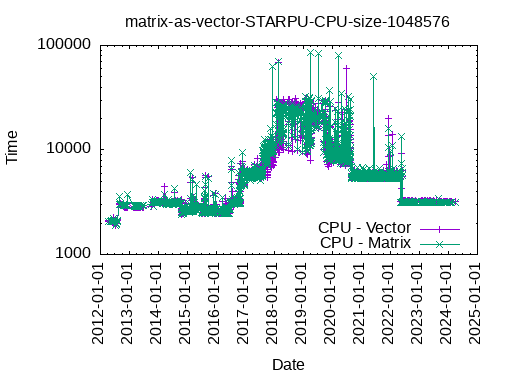
Registering a Matrix as a Vector