Features
Portability
Portability is obtained by the means of a unified abstraction of the machine. StarPU offers a unified offloadable task abstraction named codelet. Rather than rewriting the entire code, programmers can encapsulate existing functions within codelets. In case a codelet can run on heterogeneous architectures, it is possible to specify one function for each architecture (e.g. one function for CUDA and one function for CPUs). StarPU takes care of scheduling and executing those codelets as efficiently as possible over the entire machine, include multiple GPUs. One can even specify several functions for each architecture (new in v1.0) as well as parallel implementations (e.g. in OpenMP), and StarPU will automatically determine which version is best for each input size (new in v0.9). StarPU can execute them concurrently, e.g. one per socket, provided that the task implementations support it (which is the case for MKL, but unfortunately most often not for OpenMP).
Genericity
The StarPU programming interface is very generic. For instance, various data structures are supported mainline (vectors, dense matrices, CSR/BCSR/COO sparse matrices, …), but application-specific data structures can also be supported, provided that the application describes how data is to be transferred (e.g. a series of contiguous blocks). That was for instance used for hierarchically-compressed matrices (h-matrices).
Data Transfers
To relieve programmers from the burden of explicit data transfers, a high-level data management library enforces memory coherency over the machine: before a codelet starts (e.g. on an accelerator), all its data are automatically made available on the compute resource. Data are also kept on e.g. GPUs as long as they are needed for further tasks. When a device runs out of memory, StarPU uses an LRU strategy to evict unused data. StarPU also takes care of automatically prefetching data, which thus permits to overlap data transfers with computations (including GPU-GPU direct transfers) to achieve the most of the architecture. Support is included for for matrices, vectors, n-dimension tensors, compressed matrices (CSR, BCSR, COO), and the application can define its own data interface for arbitrary data representation (that can even be e.g. a C++ or Python object).
Dependencies
Dependencies between tasks can be given either of several ways, to provide the programmer with the best flexibility:
- implicitly from RAW, WAW, and WAR data dependencies.
- explicitly through tags which act as rendez-vous points between tasks (thus including tasks which have not been created yet),
- explicitly between pairs of tasks,
These dependencies are computed in a completely decentralized way, and can be introduced completely dynamically as tasks get submitted by the application while tasks previously submitted are being executed.
StarPU also supports an OpenMP-like reduction access mode (new in v0.9).
It also supports a commute access mode to allow data access commutativity (new in v1.2).
It also supports transparent dependencies tracking between hierarchical sub-pieces of data through asynchronous partitioning, allowing seamless concurrent read access to different partitioning levels (new in v1.3).
Heterogeneous Scheduling
StarPU obtains portable performances by efficiently (and easily) using all computing resources at the same time. StarPU also takes advantage of the heterogeneous nature of a machine, for instance by using scheduling strategies based on auto-tuned performance models. These determine the relative performance achieved by the different processing units for the various kinds of task, and thus permits to automatically let processing units execute the tasks they are the best for. Various strategies and variants are available. Some of them are centralized, but most of them are completely distributed to properly scale with large numbers of cores. /dmdas/ (a data-locality-aware MCT strategy, thus similar to heft but starts executing tasks before the whole task graph is submitted, thus allowing dynamic task submission and a decentralized scheduler, as well as an energy optimizing extension), /eager/ (dumb centralized queue), /lws/ (distributed locality-aware work-stealing), … The overhead per task is typically around the order of magnitude of a microsecond. Tasks should thus be a few orders of magnitude bigger, such as 100 microseconds or 1 millisecond, to make the overhead negligible. The application can also provide its own scheduler, to better fit its own needs.
Clusters
To deal with clusters, StarPU can nicely integrate with MPI, through explicit or implicit support, according to the application’s preference.
- Explicit network communication requests can be emitted, which will then be automatically combined and overlapped with the intra-node data transfers and computation,
- The application can also just provide the whole task graph, a data distribution over MPI nodes, and StarPU will automatically determine which MPI node should execute which task, and automatically generate all required MPI communications accordingly (new in v0.9). We have gotten excellent scaling on a 256-node cluster with GPUs, we have not yet had the opportunity to test on a yet larger cluster. We have however measured that with naive task submission, it should scale to a thousand nodes, and with pruning-tuned task submission, it should scale to about a million nodes.
- Starting with v1.3, the application can also just provide the whole task graph, and let StarPU decide the data distribution and task distribution, thanks to a master-slave mechanism. This will however by nature have a more limited scalability than the fully distributed paradigm mentioned above.
- Starting with v1.4 and in the NewMadeleine network support case, StarPU automatically detects data broadcasts performed by the application, and automatically optimizes the broadcast.
Out of Core
When memory is not big enough for the working set, one may have to resort to using disks. StarPU makes this seamless thanks to its out of core support (new in v1.2). StarPU will automatically evict data from the main memory in advance, and prefetch back required data before it is needed for tasks.
Fortran Interface
StarPU comes with native Fortran bindings and examples.
OpenMP 4 -compatible Interface
K’Star provides an OpenMP 4 -compatible interface on top of StarPU. This allows to just rebuild OpenMP applications with the K’Star source-to-source compiler, then build it with the usual compiler, and the result will use the StarPU runtime.
K’Star also provides some extensions to the OpenMP 4 standard, to let the StarPU runtime perform online optimizations.
OpenCL-compatible Interface
StarPU provides an OpenCL-compatible interface, SOCL which allows to simply run OpenCL applications on top of StarPU (new in v1.0).
Simulation Support
StarPU can very accurately simulate an application execution and measure the resulting performance thanks to using the SimGrid simulator (new in v1.1). This allows to quickly experiment with various scheduling heuristics, various application algorithms, and even various platforms (available GPUs and CPUs, available bandwidth)!
All in All
All that means that the following sequential source code of a tiled version of the classical Cholesky factorization algorithm using BLAS is also (an almost) valid StarPU code, possibly running on all the CPUs and GPUs, and given a data distribution over MPI nodes, it is even a distributed version!
for (k = 0; k < tiles; k++) {
potrf(A[k,k])
for (m = k+1; m < tiles; m++)
trsm(A[k,k], A[m,k])
for (m = k+1; m < tiles; m++)
syrk(A[m,k], A[m, m])
for (m = k+1, m < tiles; m++)
for (n = k+1, n < m; n++)
gemm(A[m,k], A[n,k], A[m,n])
}
The complete example can be found inside the StarPU source, examples/cholesky/cholesky_implicit.c for single-node, and mpi/examples/matrix_decomposition/mpi_cholesky_codelets.c for distributed execution.
And Even More
StarPU provides a Python interface (new in v1.4), a Java interface (new in v1.4), an Eclipse plugin (new in v1.4)
Technical Details
Supported Architectures
Arbitrary mixtures of the following architectures are supported:
- SMP/Multicore Processors (x86, PPC, ARM, … all Debian architecture have been tested)
- CUDA NVIDIA GPUs (e.g. heterogeneous multi-GPU), with pipelined and concurrent kernel execution support (new in v1.2), GPU-GPU direct transfers (new in v1.1), and GPU-NIC direct transfers (new in v1.4)
- HIP AMD and NVIDIA GPUs (new in v1.4)
- OpenCL devices
- Maxeler FPGA (new in v1.4)
- Intel SCC (experimental, new in v1.2, removed in v1.3)
- Intel MIC / Xeon Phi (new in v1.2, removed in v1.4)
Supported Operating Systems
- GNU/Linux
- Mac OS X
- Windows
Stability
StarPU is checked every night with
- Valgrind / Helgrind
- gcc’ Address/Leak/Thread/Undefined Sanitizers
- cppcheck
- Coverity
Performance Analysis Tools
ViTE
In order to understand the performance obtained by StarPU, it is helpful to visualize the actual behavior of the applications running on complex heterogeneous multicore architectures. StarPU therefore makes it possible to generate Pajé traces that can be visualized thanks to the ViTE (Visual Trace Explorer) open source tool.
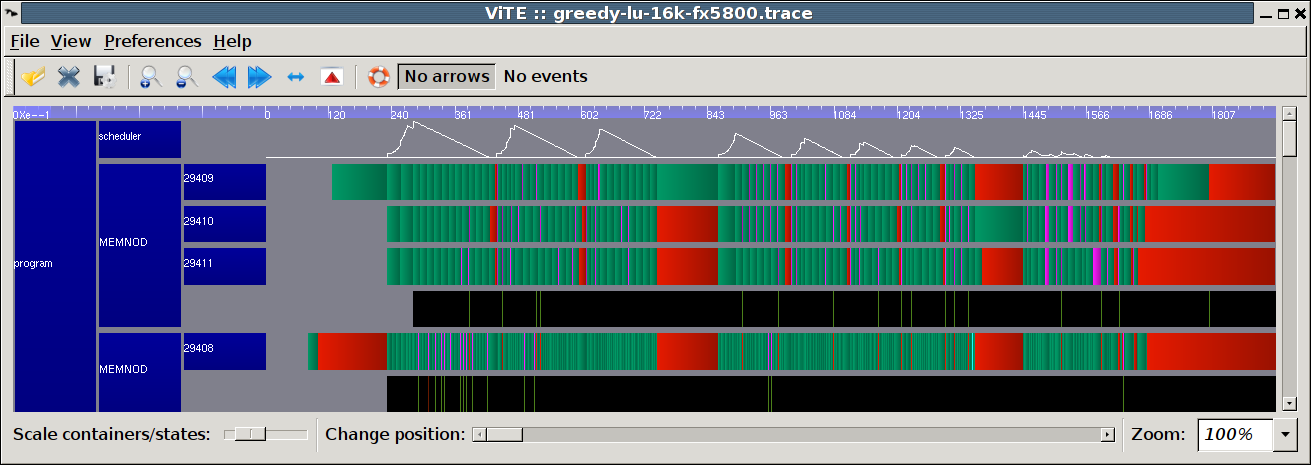
Example: LU decomposition on 3 CPU cores and a GPU using a very simple greedy scheduling strategy. The green (resp. red) sections indicate when the corresponding processing unit is busy (resp. idle). The number of ready tasks is displayed in the curve on top: it appears that with this scheduling policy, the algorithm suffers a certain lack of parallelism. Measured speed: 175.32 GFlop/s
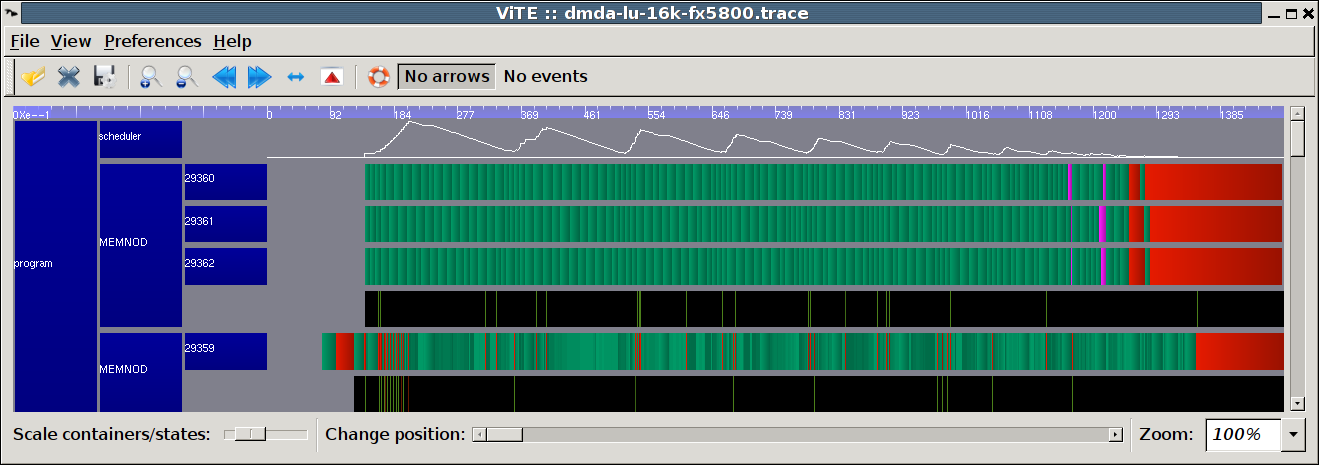
This second trace depicts the behavior of the same application using a scheduling strategy (dmda) trying to minimize load imbalance thanks to auto-tuned performance models and to keep data locality as high as possible. In this example, the Pajé trace clearly shows that this scheduling strategy outperforms the previous one in terms of processor usage. Measured speed: 239.60 GFlop/s
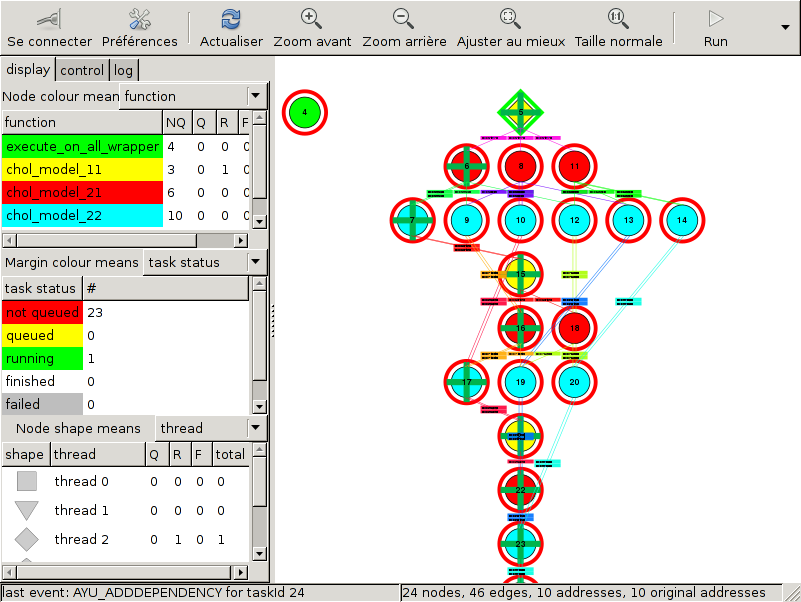
Temanejo
Temanejo can be used to debug the task graph, as shown below (new in v1.1).
StarVZ
StarVZ (paper) can be used to investigate performance, as shown below